Autores:
Chao He, Jianqiang Ren, Liefeng Bo
Lugar de trabajo:
Tongyi Lab, Alibaba Group
Correos electrónicos:
{yichao.hc, jianqiang.rjq, liefeng.bo}@alibaba-inc.com
Resumen
El estilo de dibujos animados en 2D es una forma de arte muy importante en la creación de personajes digitales, especialmente popular entre el público más joven. Aunque los avances en la tecnología de humanos digitales han impulsado muchas investigaciones sobre humanos digitales realistas y personajes en 3D, los personajes de dibujos animados interactivos en 2D han recibido menos atención. A diferencia de los personajes en 3D, que requieren una construcción compleja y un proceso de renderizado que consume muchos recursos, Live2D, un formato muy utilizado para personajes de dibujos animados en 2D, ofrece una alternativa más eficiente. Live2D permite animar personajes en 2D de manera que simulan movimientos en 3D sin necesidad de crear un modelo 3D completo. Además, Live2D utiliza un sistema de renderizado ligero basado en HTML5 (H5), lo que mejora tanto la accesibilidad como la eficiencia.
En este informe técnico, presentamos Textoon, un método innovador para generar diversos personajes de dibujos animados en 2D en formato Live2D a partir de descripciones de texto. Textoon utiliza modelos avanzados de lenguaje y visión para comprender las intenciones del texto y generar la apariencia en 2D, permitiendo crear una amplia variedad de personajes 2D impresionantes e interactivos en menos de un minuto. Puedes visitar la página del proyecto en: https://human3daigc.github.io/Textoon_webpage/.

¡Perfecto! Aquí tienes la traducción al español de España, simplificada para que sea fácil de entender:
1. Introducción
Los personajes de dibujos animados son seres ficticios que suelen destacar por su apariencia adorable y sus colores vivos. Se utilizan mucho en películas, videojuegos, redes sociales y publicidad. Estos personajes pueden crearse en estilos 2D y 3D. Aunque las animaciones en 3D ofrecen más libertad para crear y controlar, suelen ser más costosas y dependen de motores de renderizado. Por otro lado, crear personajes de dibujos animados en 2D es más sencillo y eficiente, lo que los hace especialmente adecuados para dispositivos con poca potencia, como móviles y aplicaciones web. En el mundo de los personajes 2D, Live2D[3] se ha convertido en un estándar líder para ofrecer interactividad en tiempo real.
Live2D es una tecnología que se usa para crear modelos de personajes en 2D con una interactividad similar a la de los modelos 3D. Funciona utilizando una ilustración base y un conjunto de puntos de control que definen cómo pueden moverse las diferentes partes del personaje. Estos movimientos se pueden controlar, lo que permite una amplia gama de expresiones y acciones. Live2D convierte ilustraciones 2D originales en personajes animados y dinámicos. Su interfaz 2D es fácil de usar, lo que la hace accesible para ilustradores y diseñadores principiantes. Además, los modelos ligeros son compatibles con varias plataformas, incluyendo HTML5 (H5).
Aunque Live2D ha facilitado la creación de personajes animados en 2D, los procesos detallados de capas y unión de mallas siguen siendo largos y requieren mucho esfuerzo. Además, modificar modelos existentes de Live2D para lograr apariencias diferentes sigue siendo un desafío. Para resolver estos problemas, presentamos Textoon, un sistema diseñado para generar modelos Live2D a partir de descripciones de texto. Utilizando modelos existentes de Live2D y tecnologías avanzadas de generación, Textoon permite a los usuarios crear modelos Live2D personalizados con simples instrucciones de texto. Las características principales de Textoon son:
- Análisis preciso del texto: Nuestro sistema es muy bueno extrayendo detalles de descripciones complejas. Identifica con precisión características como el pelo de atrás, el pelo de los lados, el flequillo, el color de los ojos, las cejas, la forma de la cara, el tipo de ropa y el calzado. Esto permite que los usuarios puedan dar instrucciones más flexibles.
- Generación controlable de la apariencia: Después de analizar el texto, cada componente se convierte en una plantilla completa del personaje. Los límites del contorno permiten controlar con precisión la forma del personaje, mientras que un modelo de texto a imagen se encarga de generar los colores y texturas internos.
- Editable: Si los usuarios no están satisfechos con el resultado inicial y quieren modificar detalles específicos, nuestro sistema les permite seleccionar posiciones concretas para añadir, eliminar o cambiar elementos.
- Animación: Los controles de la boca en Live2D incluyen principalmente MouthOpenY (que controla el movimiento vertical de la boca) y MouthForm (que ajusta las expresiones, como sonreír o fruncir el ceño). Sin embargo, estos controles no siempre ofrecen los mejores resultados. Para mejorar la precisión de las animaciones de habla, integramos las capacidades de ARKit (una herramienta de animación facial) en la función de sincronización de labios de Live2D. Esto aumenta el realismo y la precisión de las animaciones.
Nuestras principales contribuciones en este trabajo son:
- Hasta donde sabemos, Textoon es el primer método que permite generar personajes Live2D a partir de descripciones de texto, capaz de crear un nuevo personaje 2D en menos de un minuto sin necesidad de unir manualmente las partes.
- Hemos ajustado un modelo de lenguaje (LLM) para extraer con precisión términos descriptivos de cada parte del cuerpo a partir de textos complejos, asegurando que los resultados generados se ajusten a lo que el usuario describe. Además, utilizamos modelos de texto a imagen para crear una gran variedad de personajes 2D animados y llamativos.
- Al mejorar el mecanismo de animación facial de Live2D, hemos logrado que las expresiones faciales sean mucho más realistas y expresivas.
2. Trabajos relacionados
Texto a humano digital: ChatAvatar[13] es una herramienta que utiliza descripciones de texto para generar recursos faciales con texturas de ultra alta resolución, revolucionando el proceso tradicional de creación de recursos en 3D. Usa un modelo de difusión y una base de datos completa de recursos faciales para producir elementos generados por ordenador (CG) que son compatibles con los motores de renderizado más comunes. Esto simplifica la experiencia del usuario, ya que todo se hace a través de interacciones basadas en texto. Sin embargo, los resultados generados son incompletos y carecen de elementos como el pelo, los ojos, el cuerpo y la ropa, lo que dificulta su uso directo por parte de los usuarios.
Make-A-Character[8] permite a los usuarios crear humanos digitales en 3D de alta calidad, completamente detallados y animables, a través de simples descripciones de texto. Los usuarios pueden especificar características como la forma de la cara, los rasgos de los ojos, el color del iris, los peinados y sus colores, el tipo de cejas, boca y nariz, e incluso añadir arrugas y pecas. Sin embargo, los resultados generados requieren un motor de renderizado potente y tienen un alto coste computacional para mostrarse.
Modelos de difusión y ControlNet: Stable Diffusion (SD)[9] es un ejemplo de las potentes capacidades de los modelos de difusión. Utiliza el marco UNet para generar imágenes de forma iterativa basándose en descripciones de texto. ControlNet[12] mejora el control y la flexibilidad de los modelos generativos, incluyendo los modelos de difusión. Introduce señales de control o restricciones adicionales en el proceso de generación, lo que mejora la precisión y coherencia de los resultados. Este enfoque amplía significativamente las aplicaciones y casos de uso de los modelos generativos. A través de métodos de generación condicional, ControlNet puede producir datos de alta calidad que cumplen con requisitos específicos, mostrando un gran potencial en áreas como la creación artística, la realidad virtual y la producción de películas.
Modelos de lenguaje grandes (LLMs): Los Modelos de Lenguaje Grandes (LLMs, por sus siglas en inglés) suelen referirse a modelos de lenguaje con cientos de miles de millones de parámetros o incluso más. Utilizando grandes cantidades de datos, hardware potente y arquitecturas Transformer[10], estos modelos han alcanzado un tamaño sin precedentes. Investigaciones tempranas sobre LLMs, como T5[6], emplearon técnicas de aprendizaje por transferencia. Más tarde, GPT-3[2] demostró que los LLMs podían realizar tareas específicas sin necesidad de ajustes adicionales (zero-shot). Cuando se les proporciona una descripción de la tarea y ejemplos, los LLMs pueden generar respuestas precisas. Por ejemplo, el último modelo Qwen2.5[11], entrenado con un conjunto de datos enorme de 18 billones de tokens, destaca por seguir instrucciones, generar textos largos, entender datos estructurados y producir resultados estructurados.
3. Generación de Live2D
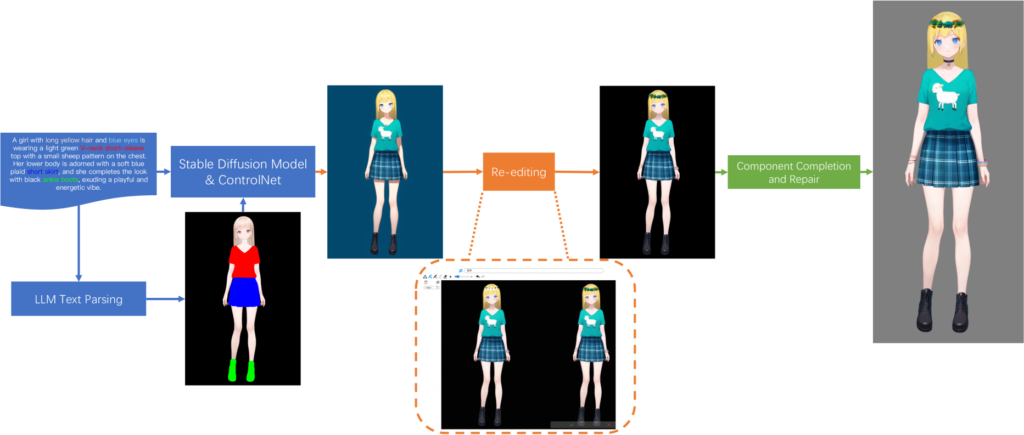
Esta sección explica en detalle nuestro enfoque. Comenzamos con una breve revisión de los principios de funcionamiento de Live2D y presentamos nuestro método de división de componentes, diseñado para aumentar la diversidad en la generación. Luego, presentamos los módulos que hemos creado para el análisis de texto, la generación controlable de apariencias, la re-edición y la finalización de componentes. Estos módulos nos permiten generar un personaje Live2D completamente nuevo a partir de una sola frase en menos de un minuto, como se muestra en la Figura 2.
3.1 Conceptos básicos de Live2D
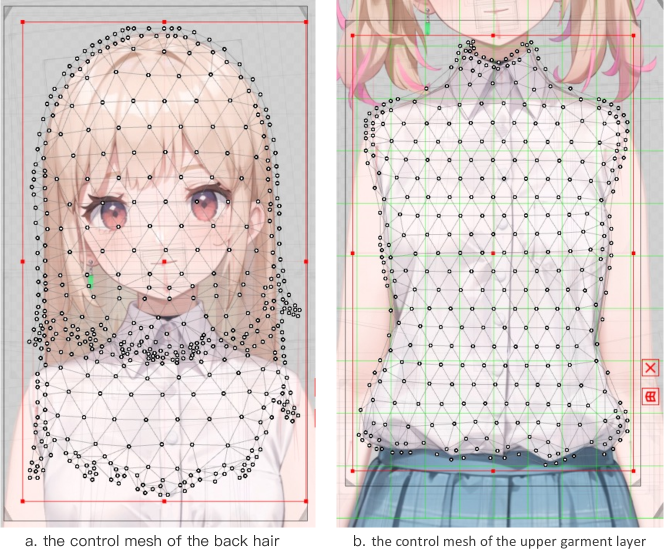
Un personaje típico de Live2D está compuesto por varias capas, como el cuerpo, la ropa, el pelo y otros elementos. Cada capa se divide en una malla de polígonos que controla las diferentes partes del personaje 2D, como se ilustra en la Figura 3. Esta composición por capas permite deformaciones suaves al manipular la posición de los puntos de la malla.
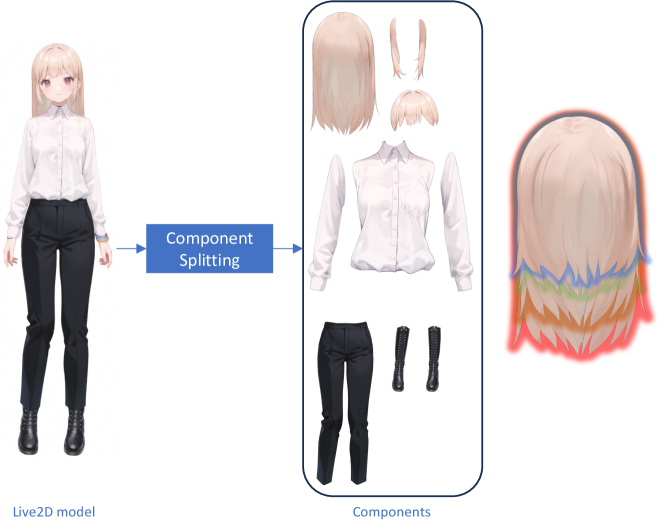
3.2 División de componentes
Dado que los modelos de Live2D están compuestos por muchas capas, decidimos fusionar algunas de las capas más pequeñas y detalladas para reducir el número total de capas. Aunque esto puede afectar ligeramente la expresividad de los movimientos detallados, simplifica el proceso de generación. Para cada parte del cuerpo, optamos por usar elementos más grandes para generar elementos a menor escala, lo que aumenta la diversidad de los modelos. Como se muestra en la Figura 4, el elemento de «pelo largo» puede usarse para crear variaciones de «pelo corto».
3.3 Análisis de texto
Necesitamos extraer las partes del cuerpo correspondientes a partir de la descripción de texto y luego combinarlas para controlar el siguiente paso de la generación. Los modelos de lenguaje grandes (LLMs) no pueden extraer directamente las palabras adecuadas para cada componente a partir de textos complejos y variados. Para solucionar esto, generamos textos descriptivos combinando aleatoriamente componentes existentes con palabras de uso común, creando así 640,000 pares de texto-componente. Estos datos generados se utilizan para ajustar el modelo Qwen2.5-1.5B[11]. Como se muestra en la Figura 5, podemos extraer con precisión las categorías de los componentes a partir de textos complejos en cuestión de milisegundos y utilizando solo 4GB de memoria (con una tarjeta RTX 4090), logrando una tasa de precisión superior al 90%.

3.4 Controllable Appearance Generation
The facial proportions of 2D cartoon characters tend to remain consistent, with their unique traits primarily found in their hair, clothing, and accessories. Furthermore, the high resolution of 2D original artwork makes the choice of image generation model especially important.
We evaluated the top text-to-image models based on control accuracy, generation quality, text relevance, and their ability to create text or patterns. Ultimately, we selected SDXL [5] as the optimal choice. SDXL excels in controllability, produces images with sharp edges, and supports a maximum resolution of 1024 pixels. Additionally, it handles long text descriptions effectively and generates precise text patterns accurately.
To maintain the model’s driving performance, it is essential that the generated output adhere to the specified areas for each component. In our template model, we categorize the components as follows: 5 types of back hair, 3 types of mid hair, 3 types of front hair, 5 types of tops, 6 types of sleeves, 5 types of pants, 5 types of skirts, and 6 types of shoes, as shown in Fig. 6. By combining these components and utilizing the control features of the base model, we have managed to achieve a wide variety of outputs while preserving the original driving performance.

3.5 Re-edición
Utilizamos una técnica de edición de imágenes[4] que permite a los usuarios dibujar libremente áreas específicas y añadir anotaciones de texto para refinar los detalles de la imagen inicial del personaje. Una vez que el usuario está satisfecho con los ajustes, la imagen modificada se convierte en la apariencia final del personaje.
3.6 Finalización de componentes
Una vez que se establece la imagen final del personaje, el siguiente paso consiste en analizar la imagen y colocar con precisión cada componente en sus respectivas capas. Este proceso presenta dos desafíos principales. El primero es lograr una segmentación a nivel de píxel para cada componente, una tarea que sigue siendo difícil incluso utilizando el método SAM2[7]. El segundo desafío es manejar las áreas ocultas.
Para abordar el primer desafío, utilizamos una plantilla generada por el mecanismo de control como máscara para extraer los píxeles directamente de la imagen original. Para el segundo desafío, primero rellenamos las áreas ocultas con píxeles de las regiones no ocultas y luego aplicamos un proceso de generación controlada de imagen a imagen para refinar el resultado. Por ejemplo, al restaurar el pelo de la parte trasera, que está mayormente oculto por la cabeza (Figura 7), primero eliminamos los píxeles de la cabeza y luego usamos una técnica de reconstrucción basada en imagen a imagen. Este método no solo evita la generación de contenido no deseado, sino que también garantiza la coherencia de color con el pelo de la parte delantera.

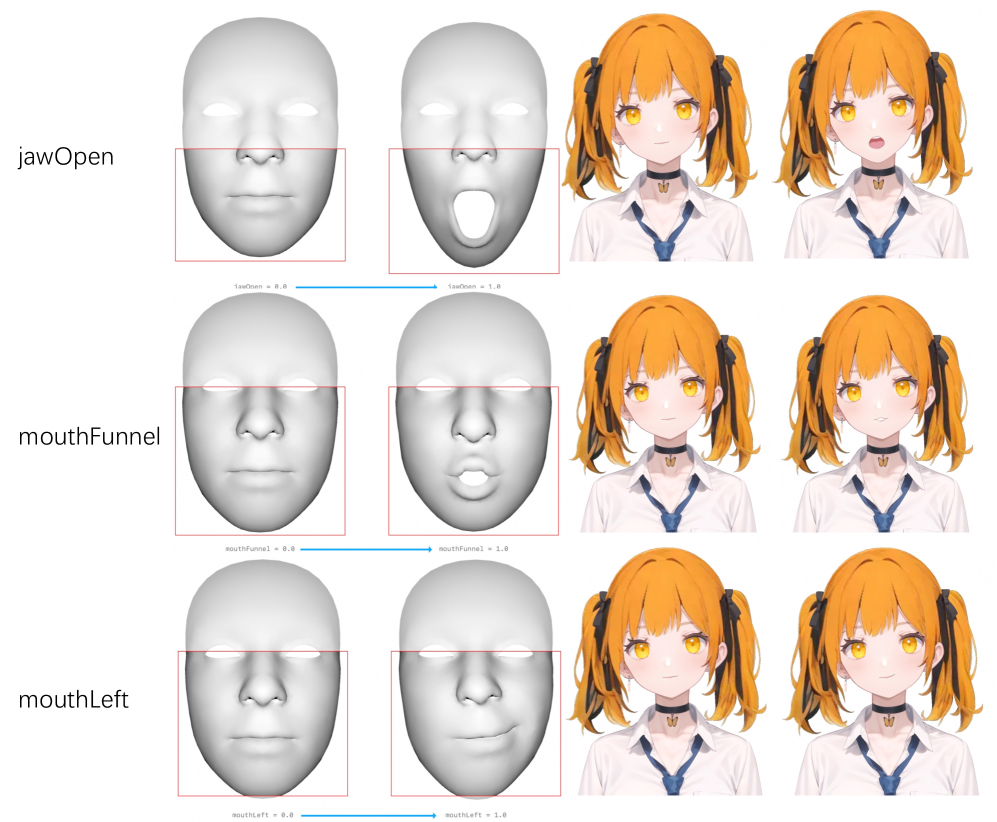
3.7 Animación
La mayoría de los modelos de Live2D suelen depender de solo dos parámetros (MouthOpenY y MouthForm) para sincronizar los labios con el audio, lo que limita las interacciones dinámicas. En cambio, ARKit[1] ofrece 52 parámetros para capturar expresiones faciales detalladas. Inspirándonos en el amplio conjunto de parámetros de ARKit, hemos desarrollado parámetros más completos para la sincronización de labios, como se muestra en la Figura 8. Al crear formas de boca en Live2D que se corresponden con el marco de ARKit, mejoramos significativamente la vivacidad y expresividad de las animaciones del modelo, como se demuestra en la Figura 9.

4. Resultados
Combinando los módulos mencionados anteriormente, nuestro sistema es capaz de generar un personaje Live2D controlable, estéticamente atractivo y listo para animar, basado en una sola frase, en menos de un minuto. La Figura 10 muestra algunos de los resultados generados, que validan la eficacia de nuestro método en términos de atractivo visual y diversidad.
5. Limitaciones
Aunque aplicamos de manera innovadora modelos generativos a la creación de personajes Live2D, permitiendo la generación automática de diversos avatares de dibujos animados en 2D, todavía existen algunas limitaciones. En primer lugar, nuestro proceso depende de textos de entrada para generar los personajes Live2D, pero los textos tienen dificultades para transmitir información compleja y matizada, lo que hace que la generación controlada de detalles sea un desafío. En segundo lugar, los resultados generados están limitados por la disposición de las capas de componentes en los modelos originales de Live2D, ya que hay una variedad limitada de estilos de componentes disponibles.

6. Conclusión
Presentamos Textoon, el primer método para generar personajes de dibujos animados Live2D a partir de descripciones de texto. Al aprovechar modelos avanzados de lenguaje y visión, Textoon puede crear rápidamente una variedad de personajes 2D interactivos y visualmente impresionantes en menos de un minuto. También integramos formas faciales compatibles con ARKit, lo que mejora los movimientos de la boca para interacciones más expresivas, permitiendo conversaciones animadas con los usuarios. Los personajes de dibujos animados Live2D generados pueden renderizarse sin problemas utilizando HTML5, lo que abre un amplio abanico de posibilidades de aplicación.
Referencia: